Create AI Embedding app using Supabase & SvelteKit
A few weeks back, Supabase shared an exciting customer story about the Quivr app. Quivr allows users to have dynamic conversations with their second brain or knowledge base, effortlessly importing content from various formats like text, PDFs, web page URLs, and audio. Quivr’s backend runs on Python, utilizing FastAPI and Langchain, while the frontend is powered by Next.js. In this post, we’ll simplify the process by creating a Quivr-like app using SvelteKit and Supabase.
We’ll kick off with my previous Supabase project, Supalytic (a runner-up in the Supabase hackathon, check it out here). It’s already configured with Supabase auth and a database tailored for SvelteKit SSR.
For a foundational understanding of pg_vector and embedding integration with Supabase, refer to the informative blog post by Supabase. It’s an excellent resource to get started.
Feature Plan
In building this app, our aim is a simple knowledge base. Users can input and store text, generate embeddings using OpenAI, save the vectors on Supabase, and use them later for contextual chat. To keep things straightforward, we’re focusing on text content for now.
Building App
As mentioned earlier, I’m utilizing the starter project from Supalytic. This saves me from setting up the web app portion since it already comes equipped with Tailwind CSS, Supabase authentication, and a pre-configured database. I’ve streamlined the code by removing any unrelated components from Supalytic.
The next step involves creating a migration using the Supabase CLI. You can find detailed instructions in the Supabase documentation here. Below is our finalized migration script for the app:
-- Enable the pgvector extension to work with embedding vectors
CREATE EXTENSION IF NOT EXISTS vector;
-- Create a table to store your documents
CREATE TABLE documents (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
knowledge_id UUID,
content TEXT,
embedding VECTOR(1536) -- 1536 works for OpenAI embeddings, change if needed
);
-- Add a HNSW index for the inner product distance function
CREATE INDEX ON documents
USING hnsw (embedding vector_ip_ops);
-- Create a table to store knowledge entries
CREATE TABLE knowledges (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
user_id UUID,
title VARCHAR,
created_at TIMESTAMP DEFAULT NOW()
);
-- Create or replace a function to match documents with knowledge references
CREATE OR REPLACE FUNCTION match_documents (
knowledge_id UUID,
query_embedding VECTOR(1536),
match_threshold FLOAT,
match_count INT
)
RETURNS TABLE (
id UUID,
knowledge_id UUID,
content TEXT,
similarity FLOAT
)
LANGUAGE SQL STABLE
AS $$
SELECT
documents.id,
documents.knowledge_id,
documents.content,
1 - (documents.embedding <=> query_embedding) AS similarity
FROM documents
WHERE documents.knowledge_id = knowledge_id
AND 1 - (documents.embedding <=> query_embedding) > match_threshold
ORDER BY similarity DESC
LIMIT match_count;
$$;
With the recent release of HNSW index support by Supabase (check it out here), we’re excited to implement it in our app for enhanced performance. Let’s leverage this feature to optimize the efficiency of our application.
The next crucial step is to generate embeddings when content is added to the knowledge base. Here’s a snippet of the action handler from our project:
import type { Actions } from './$types';
import OpenAI from 'openai';
import { env } from '$env/dynamic/private';
export const actions = {
default: async ({ request, params, locals: { db } }) => {
const form = await request.formData();
const content = form.get('content')?.toString() ?? '';
const openai = new OpenAI({ apiKey: env.OPENAI_KEY });
const embeds = await openai.embeddings.create({
input: content,
model: 'text-embedding-ada-002'
});
const [{ embedding }] = embeds.data;
const response = await db.from('documents').insert({
content,
embedding,
knowledge_id: params.id
});
}
} satisfies Actions;
At this stage, we’ve successfully stored knowledge base content with embedding vectors in the Supabase database. Moving forward, our next step is to incorporate queries from the knowledge base into the user’s chat context. Let’s seamlessly integrate these elements for a more dynamic and interactive experience.
To enhance interactivity, we’ll utilize the OpenAI stream response. Luckily, SvelteKit simplifies the handling of such streams through Server-Sent Events (SSE), facilitating the seamless transmission of streamed responses from the server to the client UI. Here’s how it looks in TypeScript:
import OpenAI from 'openai';
import type { RequestHandler } from './$types';
import { encode } from 'gpt-tokenizer/esm/model/gpt-3.5-turbo';
import { env } from '$env/dynamic/private';
export const POST: RequestHandler = async ({ request, params, locals: { db } }) => {
const form = await request.json();
const content = form.prompt;
const openai = new OpenAI({ apiKey: env.OPENAI_KEY });
const embeds = await openai.embeddings.create({
input: content,
model: 'text-embedding-ada-002'
});
const [{ embedding }] = embeds.data;
const { data: documents, error } = await db.rpc('match_documents', {
knowledge_id: params.id,
query_embedding: embedding,
match_threshold: 0.78, // Choose an appropriate threshold for your data
match_count: 10 // Choose the number of matches
});
console.log('error', error);
const maxToken = 1500;
let tokenCount = 0;
let contextText = '';
console.log('documents count', documents?.length);
if (documents) {
for (let i = 0; i < documents.length; i++) {
const doc = documents[i];
const encoded = encode(doc.content);
console.log('doc id', doc.id, 'token length:', encoded.length);
tokenCount += encoded.length;
if (tokenCount > maxToken) {
break;
}
contextText += `${doc.content.trim()}\n---\n`;
}
}
console.log('context', contextText);
console.log('----\n\n');
let prompt = `You are a very enthusiastic Assistant who loves to help people! Given the following sections from the personal knowledge base, answer the question using only that information, outputted in markdown format. If you are unsure and the answer is not explicitly written in the documentation, say "Sorry, I don't know how to help with that".`;
prompt += `
Context sections:
${contextText}
Question: """
${content}
"""
Answer as markdown (including related code snippets if available) and use same language as question language event if you dont know:
`;
const complete = await openai.completions.create({
model: 'gpt-3.5-turbo-instruct',
prompt,
max_tokens: 1500,
temperature: 0,
stream: true
});
const stream = new ReadableStream({
async start(controller) {
for await (const part of complete) {
const line = part.choices[0]?.text || '';
controller.enqueue(line);
}
controller.close();
},
cancel() {
console.log('abort stream');
complete.controller.abort();
}
});
return new Response(stream, {
headers: {
'Content-Type': 'text/event-stream'
}
});
};
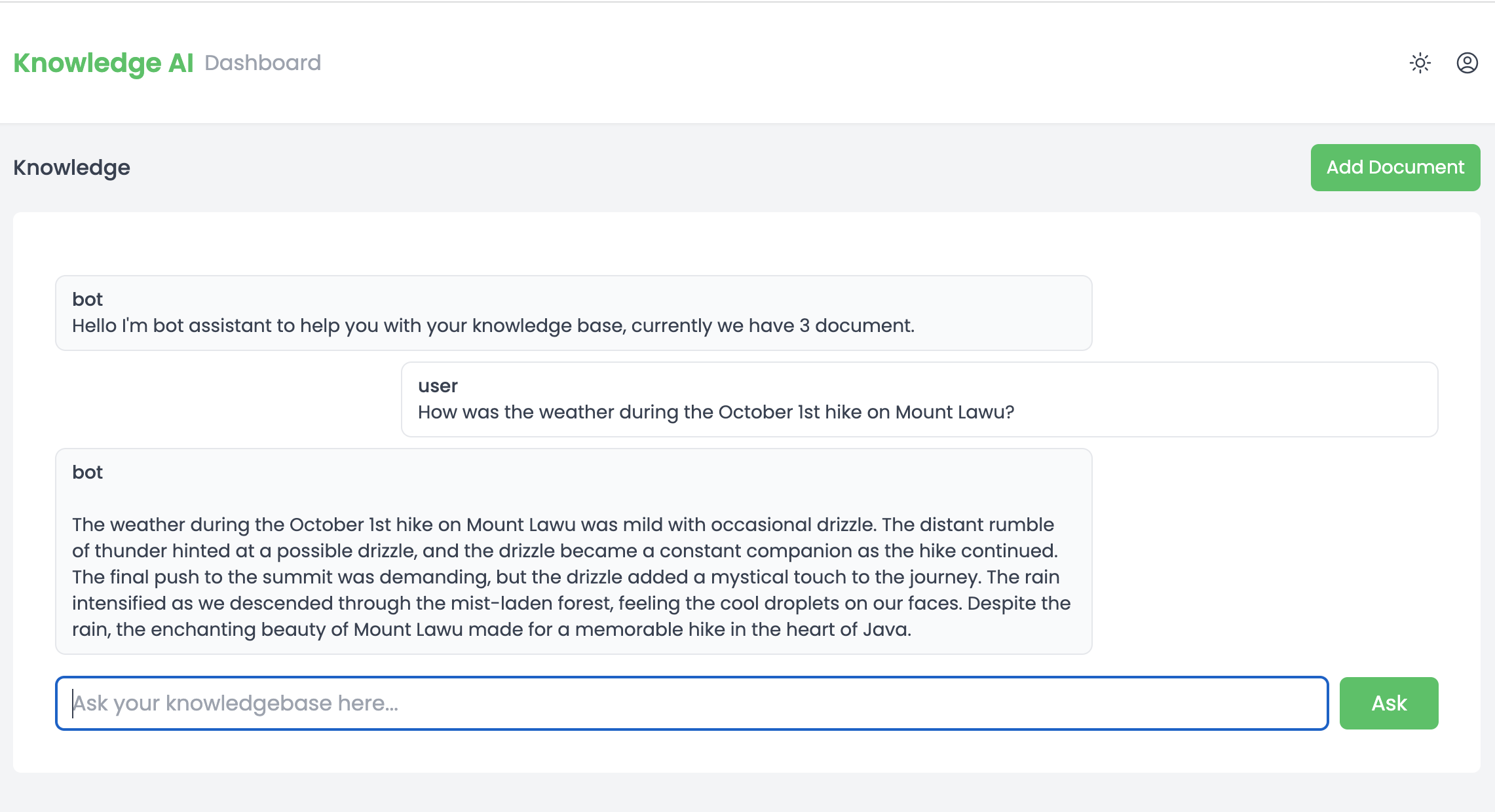
And that concludes the overview. Delving into detailed code explanations would exceed the scope of a single post. However, if you’re keen on exploring the nitty-gritty details, feel free to explore the GitHub repository: Knowledge AI. Also, check out this snapshot of my interaction with the notes:
Happy coding!